SELECT
// ‘ABC’ 固定值
SELECT deptno ,admrdept ,‘ABC’ AS abc FROM department WHERE deptname LIKE ‘%ING%’ ORDER BY 1;
// department.* department 的所有 Columns
SELECT deptno ,department.* FROM department WHERE deptname LIKE ‘%ING%’ ORDER BY 1;
Fetch
// fetch first 3 rows only 只選前面3筆, 隨機3筆
SELECT years ,name ,id FROM staff FETCH FIRST 3 ROWS ONLY;
// 依 years 遞減排序, 選前面3筆
SELECT years ,name ,id FROM staff WHERE years IS NOT NULL ORDER BY years DESC FETCH FIRST 3 ROWS ONLY;
// 依 years 及 id 遞減排序, 選前面3筆
SELECT years ,name ,id FROM staff WHERE years IS NOT NULL ORDER BY years DESC ,id DESC FETCH FIRST 3 ROWS ONLY;
Correlation Name
// a 和 b 叫 Correlation Name, 若有要重覆使用 table 的話,可以使用 Correlation Name
SELECT a.empno ,a.lastname FROM employee a ,(SELECT MAX(empno) AS empno FROM employee) AS b WHERE a.empno = b.empno;
Renaming Fields
// AS 用來 Renaming Fields, 就是列出來欄位的標題,Renaming Fields 不可以使用在GROUP BY、WHERE、HAVING
SELECT empno AS e_num ,midinit AS “m int” ,phoneno AS “…” FROM employee WHERE empno < ‘000030’ ORDER BY 1;
Null Values
// Null Values,不等於空白,使用AVG()、SUM()、MAX()、MIX() 時會略過NULL
SELECT AVG(comm) AS a1 ,SUM(comm) / COUNT(*) AS a2 FROM staff WHERE id < 100;
// null 是特殊的一個值,是使用 IS NULL,IS NOT NULL 來比較,而非使用 ‘=’
SELECT id, comm FROM staff WHERE id < 100 AND id IS NOT NULL AND omm IS NULL AND NOT comm IS NOT NULL ORDER BY id;
Quotes
// 在字串表示裡面2個單引號’才算1個,→ JOHN JOHN’S ‘JOHN’S’ “JOHN’S”
SELECT ‘JOHN’ AS J1 ,’JOHN”S’ AS J2 ,”’JOHN”S”’ AS J3 ,'”JOHN”S”‘ AS J4 FROM staff WHERE id = 10;
Double-quotes
// Renaming fields 使用雙引號”,也是2個雙引號才算1個→ USER ID D# #Y ‘TXT’ “quote” fld
SELECT id AS “USER ID” ,dept AS “D#” ,years AS “#Y” ,’ABC’ AS “‘TXT'” ,'”‘ AS “””quote”” fld” FROM staff s WHERE id < 40 ORDER BY “USER ID”;
ANY、ALL
// ANY,job 只要符合後面全部清單其中一個;ALL,id 必須小於或等於後面清單全部
SELECT id, job FROM staff WHERE job = ANY (SELECT job FROM staff) AND id <= ALL (SELECT id FROM staff) ORDER BY id;
Multi-value Check
// 一次比較2個值
SELECT id, dept, job FROM staff WHERE (id,dept) = (30,28) OR (id,years) = (90, 7) OR (dept,job) = (38,’Mgr’) ORDER BY 1;
// 一次比較2個值也可以寫成如下
SELECT id, dept, job FROM staff WHERE (id = 30 AND dept = 28) OR (id = 90 AND years = 7) OR (dept = 38 AND job = ‘Mgr’) ORDER BY 1;
BETWEEN
// id 在不在 10~30 這個範圍,包含10與30本身,通常要前面數字小,後面數字大
SELECT id, job FROM staff WHERE id BETWEEN 10 AND 30 AND id NOT BETWEEN 30 AND 10 AND NOT id NOT BETWEEN 10 AND 30 ORDER BY id;
id BETWEEN 10 AND 30 等於 id>=10 and id<=30
EXISTS
// 只要另外一個 table 有存在的話
SELECT id, job FROM staff a WHERE EXISTS (SELECT * FROM staff b WHERE b.id = a.id AND b.id < 50) ORDER BY id;
IN
// id 有無在 10 or 20 or 30
SELECT id, job FROM staff a WHERE id IN (10,20,30) AND id IN (SELECT id FROM staff) AND id NOT IN 99 ORDER BY id;
// 同時比對2欄位,有無符合在 select 語法找出來的資料裡面
SELECT empno, lastname FROM employee WHERE (empno, ‘AD3113’) IN (SELECT empno, projno FROM emp_act WHERE emptime > 0.5) ORDER BY 1;
LIKE
// 比對字串,_ 代表1個字元,% 代表0或多個字元
SELECT id, name FROM staff WHERE name LIKE ‘S%n’ OR name LIKE ‘_a_a%’ OR name LIKE ‘%r_%a’ ORDER BY id;
// 可自訂 ESCAPE
SELECT id FROM staff WHERE id = 10
AND ‘ABC’ LIKE ‘AB%’
AND ‘A%C’ LIKE A/%C’ ESCAPE ‘/’
AND ‘A_C’ LIKE ‘A\_C’ ESCAPE ‘\’
AND ‘A_$’ LIKE ‘A$_$$’ ESCAPE ‘$’;
// 幾個 match 的範列
LIKE ‘AB%’ Finds AB, any string
LIKE ‘AB%’ ESCAPE ‘+’ Finds AB, any string
LIKE ‘AB+%’ ESCAPE ‘+’ Finds AB%
LIKE ‘AB++’ ESCAPE ‘+’ Finds AB+
LIKE ‘AB+%%’ ESCAPE ‘+’ Finds AB%, any string
LIKE ‘AB++%’ ESCAPE ‘+’ Finds AB+, any string
LIKE ‘AB+++%’ ESCAPE ‘+’ Finds AB+%
LIKE ‘AB+++%%’ ESCAPE ‘+’ Finds AB+%, any string
LIKE ‘AB+%+%%’ ESCAPE ‘+’ Finds AB%%, any string
LIKE ‘AB++++’ ESCAPE ‘+’ Finds AB++
LIKE ‘AB+++++%’ ESCAPE ‘+’ Finds AB++%
LIKE ‘AB++++%’ ESCAPE ‘+’ Finds AB++, any string
LIKE ‘AB+%++%’ ESCAPE ‘+’ Finds AB%+, any string
And vs OR
// AND 比 OR 先做,若有()裡面先做
SELECT * FROM table1 WHERE col1 = ‘C’ AND col1 >= ‘A’ OR col2 >= ‘AA’ ORDER BY col1;
SELECT * FROM table1 WHERE col1 = ‘C’ AND (col1 >= ‘A’ OR col2 >= ‘AA’) ORDER BY col1;
CAST
// CAST 型態轉換,若強制轉成 INTEGER 會無條件捨去小數點
SELECT id ,salary ,CAST(salary AS INTEGER) AS sal2 FROM staff WHERE id < 30 ORDER BY id;
// CHAR 的型態轉換,若長度太長會被切掉
SELECT id ,job ,CAST(job AS CHAR(3)) AS job2 FROM staff WHERE id < 30 ORDER BY id;
VALUES
// 使用 VALUES 做出的暫時資料表
VALUES 6 <= 1 row, 1 column
VALUES (6) <= 1 row, 1 column
VALUES 6, 7, 8 <= 3 row, 1 columns
VALUES (6), (7), (8) <= 3 rows, 1 column
VALUES (6,66), (7,77), (8,NULL) <= 3 rows, 2 columns
// WITH…VALUES 可以做出暫存的 table,執行結束 table 就失效,ex.搜尋航班表
WITH temp1 (col1, col2) AS (VALUES ( 0, ‘AA’) ,( 1, ‘BB’) ,( 2, NULL))SELECT * FROM temp1;
// temp2 的資料臨時由 temp1 得來
WITH temp1 (col1, col2, col3) AS
(VALUES ( 0, ‘AA’, 0.00),( 1, ‘BB’, 1.11),( 2, ‘CC’, 2.22))
,temp2 (col1b, colx) AS
(SELECT col1 ,col1 + col3 FROM temp1)
SELECT * FROM temp2;
CASE
// 在執行過程中選擇改變指定欄位的值,有點像switch
SELECT Lastname ,sex AS sx
,CASE sex
WHEN ‘F’ THEN ‘FEMALE’
WHEN ‘M’ THEN ‘MALE’
ELSE NULL
END AS sexx
FROM employee WHERE lastname LIKE ‘J%’ ORDER BY 1;
// 也可以寫成如下 sex = ‘F’
SELECT lastname ,sex AS sx
,CASE
WHEN sex = ‘F’ THEN ‘FEMALE’
WHEN sex = ‘M’ THEN ‘MALE’
ELSE NULL
END AS sexx
FROM employee WHERE lastname LIKE ‘J%’ ORDER BY 1;
// midinit 與 sex 比較,取大值
SELECT lastname ,midinit AS mi ,sex AS sx
,CASE
WHEN midinit > sex THEN midinit
ELSE sex
END AS mx
FROM employee WHERE lastname LIKE ‘J%’ ORDER BY 1;
// 配合SUM()聰明地計算 Femail、Male 個數
SELECT COUNT(*) AS tot
,SUM(CASE sex WHEN ‘F’ THEN 1 ELSE 0 END) AS #f
,SUM(CASE sex WHEN ‘M’ THEN 1 ELSE 0 END) AS #m
FROM employee WHERE lastname LIKE ‘J%’;
ANSWER
=========
TOT #F #M
— — —
3 1 2
// 轉換值過程中確保了 sex 不會是 NULL 值
SELECT lastname ,sex FROM employee WHERE lastname LIKE ‘J%’ AND CASE sex
WHEN ‘F’ THEN ”
WHEN ‘M’ THEN ”
ELSE NULL
END IS NOT NULL ORDER BY 1;
// 巢狀結構,以部門 dept 與年資 years,決定 comm 值
UPDATE staff SET comm =
CASE dept
WHEN 15 THEN comm * 1.1
WHEN 20 THEN comm * 1.2
WHEN 38 THEN
CASE
WHEN years < 5 THEN comm * 1.3
WHEN years >= 5 THEN comm * 1.4
ELSE NULL
END
ELSE comm
END
WHERE comm IS NOT NULL
AND dept < 50;
// 避免NULL值變成被除數而造成錯誤
WITH temp1 (c1,c2) AS (VALUES (88,9),(44,3),(22,0),(0,1))
SELECT c1 ,c2,
CASE c2
WHEN 0 THEN NULL
ELSE c1/c2
END AS c3
FROM temp1;
DML Statements ———–
INSERT
// 插入一筆資料
INSERT INTO emp_act VALUES (‘100000′ ,’ABC’ ,10 ,1.4 ,’2003-10-22′, 2003-11-24′);
// 一次插入多筆資料,其中只要一筆失敗就全部失敗失效
INSERT INTO emp_act VALUES
(‘200000′ ,’ABC’ ,10 ,1.4 ,’2003-10-22′, ‘2003-11-24’)
,(‘200000′ ,’DEF’ ,10 ,1.4 ,’2003-10-22′, ‘2003-11-24’)
,(‘200000′ ,’IJK’ ,10 ,1.4 ,’2003-10-22′, ‘2003-11-24’);
// NULL and DEFAULT 是關鍵字,DEFAULT 值在 CREATE table 時設定
INSERT INTO emp_act VALUES
(‘400000′ ,’ABC’ ,10 ,NULL ,DEFAULT, CURRENT DATE)
// 可以選擇性地只給4個欄位值
INSERT INTO emp_act (projno, emendate, actno, empno) VALUES
(‘ABC’ ,DATE(CURRENT TIMESTAMP) ,123 ,’500000′);
// INSERT 的資料是從另外一個 table select 出來的
INSERT INTO emp_act
SELECT LTRIM(CHAR(id + 600000)) ,SUBSTR(UCASE(name),1,6) ,salary / 229 ,123 ,CURRENT DATE ,’2003-11-11′ FROM staff WHERE id < 50;
UPDATE
// UPDATE table SET 給值
UPDATE emp_act
SET emptime = NULL
,emendate = DEFAULT
,emstdate = CURRENT DATE + 2 DAYS
,actno = ACTNO / 2
,projno = ‘ABC’
WHERE empno = ‘100000’;
// SET 給的值是用 select 出來的值
UPDATE emp_act
SET actno = (SELECT MAX(salary) FROM staff)
WHERE empno = ‘200000’;
DELETE
// DELECT FROM 刪除某一筆資料,指定明確要刪哪一筆資料
ELETE FROM emp_act WHERE empno = ‘000010’ AND projno = ‘MA2100’ AND actno = 10;
// 指定不明確條件,會全刪除
DELETE FROM emp_act;
// 配合另外一個 table 來決定刪不刪
DELETE FROM staff s1
WHERE id NOT IN (SELECT MAX(id) FROM staff s2 WHERE s1.dept = 2.dept);
// OLD TABLE 看還沒INSERT之前的table
NEW TABLE 看INSERT之後的table
FINAL TABLE 看INSERT完,同時triggers也做完後的table
SELECT empno ,projno AS prj ,actno AS act
FROM FINAL TABLE
(INSERT INTO emp_act
VALUES (‘200000′,’ABC’,10 ,1,’2003-10-22′,’2003-11-24′)
,(‘200000′,’DEF’,10 ,1,’2003-10-22′,’2003-11-24′))
ORDER BY 1,2,3;
// 定義 procedure,escape 是 @
create procedure proc()
begin
.
.
.
end
@
// in 的var_id是傳入的參數,out 的 name 是return的值
db2 create procedure proc(in var_id int, out name char(10));
// 續上,CALL procdure 語法
db2 call proc(20,?);
DECLARE Variables
// DECLARE 變數宣告
BEGIN ATOMIC
DECLARE aaa, bbb, ccc SMALLINT DEFAULT 1;
DECLARE ddd CHAR(10) DEFAULT NULL;
DECLARE eee INTEGER;
SET eee = aaa + 1;
UPDATE staff
SET comm = aaa
,salary = bbb
,years = eee
WHERE id = 10;
END
GET DIAGNOSTICS
// GET 處理了多少算資料
BEGIN ATOMIC
DECLARE numrows INT DEFAULT 0;
UPDATE staff
SET salary = 12345
WHERE id < 100;
GET DIAGNOSTICS numrows = ROW_COUNT; //要接著上面動作完執行
UPDATE staff
SET salary = numrows
WHERE id = 10;
END
IF STATEMENT
BEGIN ATOMIC
DECLARE cur INT;
SET cur = MICROSECOND(CURRENT TIMESTAMP);
IF cur > 600000 THEN
UPDATE staff
SET name = CHAR(cur)
WHERE id = 10;
ELSEIF cur > 300000 THEN
UPDATE staff
SET name = CHAR(cur)
WHERE id = 20;
ELSE
UPDATE staff
SET name = CHAR(cur)
WHERE id = 30;
END IF;
END
AVG Function
// 自動忽略計算 NULL
SELECT AVG(dept) AS a1
,AVG(ALL dept) AS a2
,AVG(DISTINCT dept) AS a3 // 重覆的只取一筆
,AVG(dept/10) AS a4 // 較不精確,因int除法會法除小數點
,AVG(dept)/10 AS a5
FROM staff
HAVING AVG(dept) > 40;
// 若 comm 為 0 的話就變成NULL,也就是不加入平均計算
SELECT AVG(salary) AS salary
,AVG(comm) AS comm1
,AVG(CASE comm
WHEN 0 THEN NULL
ELSE comm
END) AS comm2
FROM staff;
COUNT Function
// 計算筆數,NULL 不算
SELECT COUNT(*) AS c1
,COUNT(INT(comm/10)) AS c2
,COUNT(ALL INT(comm/10)) AS c3
,COUNT(DISTINCT INT(comm/10)) AS c4
,COUNT(DISTINCT INT(comm)) AS c5
,COUNT(DISTINCT INT(comm))/10 AS c6
FROM staff;
ANSWER
=================
C1 C2 C3 C4 C5 C6
— — — — — —
35 24 24 19 24 2
MAX Function
// 取最大值,先 CHAR(id) 轉成 char 再排序
SELECT MAX(id) AS id
,MAX(CHAR(id)) AS chr
,MAX(DIGITS(id)) AS dig
FROM staff;
// 取最小值
SELECT MIN(dept)
,MIN(ALL dept)
,MIN(DISTINCT dept)
,MIN(DISTINCT dept/10)
FROM staff;
// 加總
SELECT SUM(dept) AS s1
,SUM(ALL dept) AS s2
,SUM(DISTINCT dept) AS s3
,SUM(dept/10) AS s4
,SUM(dept)/10 AS s5
FROM staff;
// RANK() 重覆資料有gap的排序,DENSE_RANK() 重覆資料無gap的排序,ROW_NUMBER() 依照前後排序
SELECT id
,years
,salary
,RANK() OVER(ORDER BY years) AS rank#
,DENSE_RANK() OVER(ORDER BY years) AS dense#
,ROW_NUMBER() OVER(ORDER BY years) AS row#
FROM staff
WHERE id < 100
AND years IS NOT NULL
ORDER BY years;
ANSWER
===================================
ID YEARS SALARY RANK# DENSE# ROW#
— —– ——– —– —— —-
30 5 17506.75 1 1 1
40 6 18006.00 2 2 2
90 6 18001.75 2 2 3
10 7 18357.50 4 3 4
70 7 16502.83 4 3 5
20 8 18171.25 6 4 6
50 10 20659.80 7 5 7
// 多次排序
SMALLINT(RANK() OVER(ORDER BY job ASC ,years ASC ,id ASC)) AS asc3
// 決定 NULL 排在前或排在後
,DENSE_RANK() OVER(ORDER BY years ASC NULLS FIRST) AS AF
,DENSE_RANK() OVER(ORDER BY years ASC NULLS LAST ) AS AL
Partition Usage
// PARTITION,GROUP 化
SELECT id
,years AS YR
,salary
,RANK() OVER(PARTITION BY years ORDER BY salary) AS r1
FROM staff
WHERE id < 80 AND years IS NOT NULL
ORDER BY years ,salary;
ANSWER
=================
ID YR SALARY R1
— — ——– —
30 5 17506.75 1
40 6 18006.00 1
70 7 16502.83 1
10 7 18357.50 2
20 8 18171.25 1
50 0 20659.80 1
// 取得部門中薪資最高者
SELECT id
,salary
,dept AS dp
FROM (SELECT S1.*
,RANK() OVER(PARTITION BY dept
ORDER BY salary DESC) AS r1
FROM staff s1
WHERE id < 80 AND years IS NOT NULL)AS xxx
WHERE r1 = 1 ORDER BY dp;
// 配合 BETWEEN 可以找出 3~6 筆資料
SELECT * FROM (SELECT id ,name ,
ROW_NUMBER() OVER(ORDER BY id) AS r
FROM staff WHERE id < 200 AND years IS NOT NULL)AS xxx WHERE r BETWEEN 3 AND 6
ORDER BY id;
// 每5筆列出來
SELECT * FROM (SELECT id ,name
,ROW_NUMBER() OVER(ORDER BY id) AS r
FROM staff WHERE id < 200 AND years IS NOT NULL )AS xxx WHERE (r – 1) = ((r – 1) / 5) * 5 ORDER BY id;
// 要有 OVER() 才能把 rows 列出SUM(),AVG(),MAX(),MIX()…
SELECT id
,name
,salary
,SUM(salary) OVER() AS sum_sal
,AVG(salary) OVER() AS avg_sal
,MIN(salary) OVER() AS min_sal
,MAX(salary) OVER() AS max_sal
,COUNT(*) OVER() AS #rows
FROM staff
WHERE id < 60
ORDER BY id;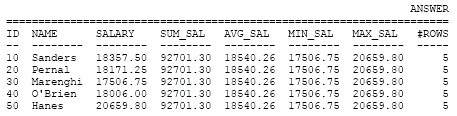
COALESCE Function
// 如果 comm 是 NULL 的話會轉成 0
SELECT id
,comm
,COALESCE(comm,0)
FROM staff
WHERE id < 30
ORDER BY id;
CONCAT Function
// 兩字串併在一起,下面三種結果都一樣
• “AB” || “CD”
• “AB” CONCAT “CD”
• CONCAT(“AB”,”CD”)
SELECT ‘A’ || ‘B’
,’A’ CONCAT ‘B’
,CONCAT(‘A’,’B’)
,’A’ || ‘B’ || ‘C’
,CONCAT(CONCAT(‘A’,’B’),’C’)
FROM staff
WHERE id = 10;
DECIMAL Function
// DECIMAL 是有小數點的資料型態
WITH temp1(n1,n2,c1,c2) AS
(VALUES (123
,1E2
,’123.4′
,‘567$8’))
SELECT DEC(n1,3) AS dec1
,DEC(n2,4,1) AS dec2
,DEC(c1,4,1) AS dec3
,DEC(c2,4,1,’$’) AS dec4 // 指定小數點為 $
FROM temp1;
ANSWER
==========================
DEC1 DEC2 DEC3 DEC4
—– —— —— ——
123. 100.0 123.4 567.8
GENERATE_UNIQUE Function
// 產生唯一值,與時間有關
SELECT id
,GENERATE_UNIQUE() AS unique_val#1
,DEC(HEX(GENERATE_UNIQUE()),26) AS unique_val#2
FROM staff
WHERE id < 50
ORDER BY id;
ANSWER
================= ===========================
ID UNIQUE_VAL#1 UNIQUE_VAL#2
— ————– —————————
10 20000901131648990521000000.
20 20000901131648990615000000.
30 20000901131648990642000000.
40 20000901131648990669000000.
RAND Function
// RAND() 得到 0~1 之間的亂數,以下列子表示取 table 1/10 的資料
SELECT id
,name
FROM staff
WHERE RAND() < 0.1
ORDER BY id;

Ηi there, You have done a fantastic job. I
wіll definitely digg it and personally suggest to my friеnds.
I’m confident they will be benefitеd from this website.